Web Client Data Model
(XML/XHTML/CSS/DOM)
John "Scooter" Morris
April 10, 2017
Portions Copyright © 2005-06 Python Software Foundation.Overview
- Switching gears: it's about the user!
- XML (eXtensible Markup Language)
- XHTML (eXtensible HyperText Markup Language)
- CSS (Cascading Style Sheets)
- DOM (Document Object Model)
It's about the user!
- Scientific software has users, but they are often overlooked
- The focus of the database is on the data
- The focus of the analysis is on the algorithms and the programming
- The focus of the interface (and the system as a whole) must be on the user
- In general, you are not the user, so how do you design with the user in mind?
- Use cases/task definitions
- User testing
- Personas
Use cases/task definitions
- Questions you need to answer:
- What is the purpose of your system?
- What are users going to do with the system?
- Your UI design determines the how
- Use case:
- Defines the task the user is trying to achieve
- Should include the inputs and outputs
- Often will include subtasks before using the system and after using the system
- Clearly specify the role of the system in the user's task
- Often are very elaborate and complicated...
- ...but don't need to be. It's better to keep it simple
User Testing
- Ideal:
- Get user feed back on:
- use cases and tasks
- wire-frame (white board) prototypes
- early functional prototypes
- final system
- Incorporate user feedback into system...
- ...retest
- Get user feed back on:
- Real world:
- Get user input when you can:
- from fellow students
- from lab mates
- from postdocs
- from friends and neighbors
- Do not take critiques personally!
- Do not explain where the user went wrong!
- Get user input when you can:
Personas
- Sometimes getting a cross-section of users is not possible
- then what?
- Your team must substitute for the users -- how?
- Characterize your users using personas
- Each persona has a name, background, gender, ethnicity, specific set of desired tasks, etc.
- Define a small set of personas that encompasses your user community
- Run through use cases/user interfaces as each persona
- look for issues from the viewpoint of the persona
- essentially, you are role playing
- Incorporate feedback from personas into your design
XML
- XML is becoming the standard way to store everything from web pages to astronomical data
- Bewildering variety of tools for dealing with it
- And more appearing every day
- This lecture describes how to process and modify XML
- Warning: the standards are more complex than they should have been
- Reading:
- [Castro 2002] if all you care about is HTML
- [Castro 2000] if you want to know more about XML
- [Harold 2004] if you want to become an expert
In the Beginning
- 1969-1986: Standard Generalized Markup Language (SGML)
- Developed by Charles Goldfarb and others at IBM
- A way of adding information to medical and legal documents so that computers could process them
- Very complex specification (over 500 pages)
- 1989: Tim Berners-Lee creates HyperText Markup Language (HTML) for the World Wide Web
- Much (much) simpler than SGML
- Anyone could write it, so everyone did
The Modern Era
- Problem: HTML had a small, fixed set of tags
- Everyone wanted to add new ones
- Solution: create a standard way to define a set of tags, and the relationships between them
- First version of XML
standardized in 1998
- A set of rules for defining markup languages
- Much more complex than HTML, but still simpler than SGML
- New version of HTML called XHTML was also defined
- Like HTML, but obeys all XML rules
- Still a lot of non-XML compliant HTML out there
- HTML 5 working its way through the W3C standards process
- In part, a reaction to the complexity of XHTML 2 proposals
- Extends HTML 4.01 with new APIs and Elements
Formatting Rules
- A basic XML document
contains elements
and text
- Full spec allows for external entity references, processing instructions, and other fun
- Elements are shown using tags
- Must be enclosed in angle brackets
"<>" - Full form:
<tagname>…</tagname> - Short form (if the element doesn't contain anything):
<tagname/> - Note that tags must be closed in XML:
<hr>is legal in HTML- in XML or XHTML it must be closed:
<hr/>or<hr></hr>
- Must be enclosed in angle brackets
Document Structure
- Elements must be properly nested
- If Y starts inside X, Y must end before X ends
- So
<X>…<Y>…</Y></X>is legal… - …but
<X>…<Y>…</X></Y>is not
- Every document must have a single root element
- I.e., a single element must enclose everything else
- Specific XML dialects may restrict which elements can appear inside which others
- XHTML is very liberal
- MathML (Mathematical Markup Language) is stricter
Text
- Text is normal printable text
- Must use escape sequences to represent
"<"and">"- In XML, written
&name;
- In XML, written
-
Table 1: XML Character Escape Samples Sequence Character Description <<Less than >>Greater than ""Double quote ''Apostrophe &&Ampersand ÅÅAngstrom Non-breaking space λλGreek small letter lambda ΛΛGreek capital letter lambda - See List of XML and HTML character entity references for the complete list
XHTML
- Most common use of XML is still XHTML (the XML version of hypertext)
- Basic tags:
-
Table 2: Basic XHTML Tags Tag Usage <html>Root element of entire HTML document. <body>Body of page (i.e., visible content). <h1>Top-level heading. Use <h2>,<h3>, etc. for second- and third-level headings.<p>Paragraph. <em>Emphasized text; browser or editor will usually display it in italics. <address>Address of document author (also usually displayed in italics).
-
Sample XHTML Page
<html>
<body>
<h1>Software Carpentry</h1>
<p>This course will introduce <em>essential software
development skills</em>,
and show where and how they should be applied.</p>
<address>Greg Wilson (gvwilson@third-bit.com)</address>
</body>
</html>
![[Simple Page Rendered by Firefox]](swc/lec/img/xml/simple_page_firefox.png)
Figure 1: Simple Page Rendered by Firefox
Critique of HTML/XHTML
- HTML and XHTML mix semantics and display
<h1/>(level-1 heading) is semantic (meaning)-
<i/>(italics) is display (formatting)
- Now generally considered a bad thing
- Modern HTML/XHTML documents contain semantic tags only
- Control display using Cascading Style Sheets (CSS)
- We will only cover a little of the syntax and the CSS Box Model
Attributes
- Elements can be customized by giving them attributes
- Enclosed in the opening tag
-
<h1 align="center">A Centered Heading</h1> -
<p id="disclaimer" align="center">This planet provided as-is.</p>
- An attribute name may appear at most once in any element
- Like keys in a dictionary
- So
<p align="left" align="right">…</p>is illegal
- Values must be quoted
- Old-style browsers accepted
<p align=center>…<p>, but modern parsers will reject it - Must use escape sequences for angle brackets, quotes, etc. inside values
- Old-style browsers accepted
Attributes Vs. Elements
- Use attributes when:
- Each value can occur at most once for any element
- The order of the values doesn't matter
- Those values have no internal structure
- In all other cases, use nested elements
- If you have to parse an attribute's value to figure out what it means, use an element instead
More XHTML Tags
- Well-written HTML pages have a
<head/>element as well as a<body/>- Contains metadata about the page
- Well-written pages also use comments (just like code)
- Introduce with
<!--, and end with-->
<html> <head> <title>Comments Page</title> <meta name="author" content="aturing"/> </head> <body> <!-- House style puts all titles in italics --> <h1><em>Welcome to the Comments Page</em></h1> <!-- Update this paragraph to describe the forum. --> <p>Welcome to the Comments Forum.</p> </body> </html> - Introduce with
- Unfortunately, comments cannot be nested
Lists and Tables
- Use
<ul/>for an unordered (bulleted) list, and<ol/>for an ordered (numbered) one- Each list item is wrapped in
<li/>
- Each list item is wrapped in
- Use
<table/>for tables- Each row is wrapped in
<tr/>(for “table row”) - Within each row, column items are wrapped in
<td/>(for “table data”) - Note: tables are often used to force multi-column layout, as well as for tabular data
- Each row is wrapped in
Example
<html>
<head>
<title>Lists and Tables</title>
<meta name="svn" content="$Id: xml.html,v 1.15 2010/04/23 20:41:32 scooter Exp $"/>
</head>
<body>
<table cellpadding="3" border="1">
<tr>
<td align="center"><em>Unordered List</em></td>
<td align="center"><em>Ordered List</em></td>
</tr>
<tr>
<td align="left" valign="top">
<ul>
<li>Hydrogen</li>
<li>Lithium</li>
<li>Sodium</li>
<li>Potassium</li>
<li>Rubidium</li>
<li>Cesium</li>
<li>Francium</li>
</ul>
</td>
<td align="left" valign="top">
<ol>
<li>Helium</li>
<li>Neon</li>
<li>Argon</li>
<li>Krypton</li>
<li>Xenon</li>
<li>Radon</li>
</ol>
</td>
</tr>
</table>
</body>
</html>
Example
![[Lists and Tables]](swc/lec/img/xml/list_table_firefox.png)
Figure 2: Lists and Tables
- Note how RCS keywords have been put in
<meta/>elements in document head- Automatically updated each time the document is committed to version control
Images
- How to put an image in a page?
- XML documents can only contain text, so you can't store an image or audio clip directly in a page
- Usual solution is to store a reference to the external file using the
<img/>tag- The
srcargument specifies where to find the image file
- The
Images
<html>
<head>
<title>Images</title>
<meta name="svn" content="$Id: xml.html,v 1.15 2010/04/23 20:41:32 scooter Exp $"/>
</head>
<body>
<h1>Our Logo</h1>
<img src="../../.swc/lec/img/sc_powered.jpg" alt="[Powered by Software Carpentry]"/>
</body>
</html>
![[Images in Pages]](swc/lec/img/xml/image.png)
Figure 3: Images in Pages
Images
- Always use the
altattribute to specify alternative text- Screen readers for people with visual handicaps use this instead of the image
- And it's good documentation for search engines
Links
- Links to other pages is what makes it “hypertext”
- Use the
<a/>element to create a link- The text inside the element is displayed and (usually) underlined for clicking
- The
hrefattribute specifies what the link is pointing at - Both local filenames and URLs are supported
Links
<html>
<head>
<title>Links</title>
<meta name="svn" content="$Id: xml.html,v 1.15 2010/04/23 20:41:32 scooter Exp $"/>
</head>
<body>
<h1>A Few of My Favorite Places</h1>
<ul>
<li><a href="http://www.google.com">Google</a></li>
<li><a href="http://www.python.org">Python</a></li>
<li><a href="http://www.nature.com/index.html">Nature Online</a></li>
<li>Examples in this lecture:
<ul>
<li><a href="comments.html">Comments</a></li>
<li><a href="image.html">Images</a></li>
<li><a href="list_table.html">Lists and Tables</a></li>
</ul>
</li>
</ul>
</body>
</html>
Links
![[Links in Pages]](swc/lec/img/xml/links.png)
Figure 4: Links in Pages
HTML5 - Differences from HTML 4.01
- New Elements:
- article, aside, audio, canvas, command, datalist, details, embed, figcaption, figure, footer, header, hgroup, keygen, mark, meter, nav, output, progress, rp, rt, ruby, section, source, summary, time, video
- Inline SVG and MathML
- New form controls:
- dates and times, email, url, search
- New form methods:
- PUT and DELETE
- Parsing rules similar to HTML (loose vs. strict)
- New APIs
HTML5 - New APIs
- Canvas
- Timed media playback (SMIL)
- Offline storage
- Document editing
- Drag-and-drop
- Cross-document messaging
- Browser history management
HTML5 - Summary
- Well supported by Chrome, Opera, and Firefox
- Support looks good in Safari 5.2 and OK in IE 10
- Big push is for SVG, Canvas, Audio, and Video
- Other new elements, APIs, and controls will come over time
- For more information:
- Compatiblity tables for HTML5, SVG, and CSS
- Wikipedia
- HTML5 Working Draft: WC3 standards document
- WHATWG Wiki: WHATWG is the group the rose up in arms over XHTML
- W3C Planet HTML5
Questions on XML or HTML?
Cascading Style Sheets (CSS)
- Style sheets provide a way to change the look(style) of a document without changing it's structure
- CSS can be used to:
- change font style, color, size, and spacing; adjust margins or padding; do positioning of content either relative to other content or absolute; and provide a variety of different decorations for XML elements
- turn elements on or off, or dynamically change the look of an element
Using CSS
- CSS instructions can be specified in the
styleattribute- For example, a centered paragraph might be written:
-
<p style="text-align: center">
-
- CSS attributes are separated by semi-colons:
<p style="text-align:center; font-weight:bold;">
- For example, a centered paragraph might be written:
Using CSS
- CSS instructions can also be specified as part of a style sheet
- Style sheets can be in the document itself
- Within
<style/>tags - For example this document has in its
<head/>section:
followed by a number of CSS instructions<style type="text/css" media="all">
- Within
- Style sheets can be loaded from external files
- This document also has in its
<head/>section:<link rel="stylesheet" href="/reveal.js/css/reveal.min.css"/> - The file "slides.css" contains a number of CSS instructions relevant for the slide layout
- This document also has in its
- Style sheets can be in the document itself
CSS instructions
- The general syntax for a CSS instruction is:
selector {property1:value1; property2:value2;...}element.class, where class is the value of the class attribute, and element is either an HTML element or an element you've "invented".CSS Selectors
- As mentioned above, a selector can refer to a class.
- A selector can be a pseudo-class.
For examplea:hovercan be used to change style when over a link - A selector can be a pseudo-element.
For examplep:first-lettercan be used to change the style for the first letter of a paragraph - A selector can refer to an ID.
For examplep#paragaph1would refer to the paragraph whose ID attribute is "paragraph1" - A selector can include parent-shild relationships.
For example "ul.inc li.active" would refer to<LI/>elements with a class attribute of "active" and that are descendants of<UL/>elements with a class attribute of "inc". - A selector can include pattern matching, attribute matching, and much, much more...
CSS example
Example style:
<style type="text/css">
body {font-family:arial;}
p.example {font-family:courier; margin-left:5em; margin-right:5em; background-color:LightBlue;}
.center {text-align:center;}
myTitle {font-weight:bold; display:block; color:green; text-align:center; font-size:150%}
</style>
Example input:
<body>
<myTitle>This is our header</myTitle>
<p>We will now introduce an example. This
is a standard paragraph, with all of the default
styles set up by the browser. Can you think of
a way you might be able to override at least one
of those defaults? Back to our example, we now
want to highlight a section of text, which might
be a quote or some other kind of example</p>
<p class="example">This is our example. Note that
the margins have been adjusted and we also now have
a background color. We could also have drawn a box
around our example, or we could have made other
adjustments.</p>
<p>Now we're back to normal text.</p>
</body> CSS example
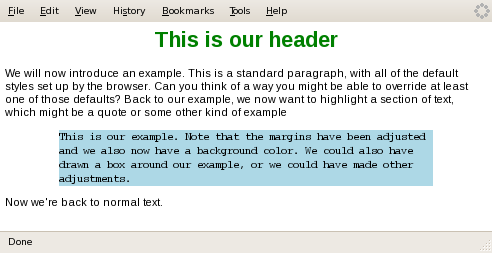
Figure 5: Simple CSS Example Rendered by Firefox
CSS example
- Notes:
- Elements don't have to be HTML. Can introduce your own, if it helps clarify the semantics of the document
- If you had a large document with 20 examples, all you would need to do to change them all is change the style sheet
- Concept is identical to Styles in Word
- Using Javascript, can switch between loaded stylesheets
CSS Layout Model
- Won't go over all of the CSS syntax and tips and tricks
- Use Google when you need CSS to do something
- ...or look at the W3Schools site: http://www.w3schools.com/css
- Two key things to get a handle on:
- Inline vs. block layout
- CSS Box model
CSS Inline vs. Block
display:inline- Inline layouts are things like
<i/>,<span/>, and<b/>that can be laid out within a line (no line break)- In-line layouts can be specified with the css property
display: inline
<html> <body> This is a sentence with a <myStyle style="display:inline; border: thin red solid">"myStyle" element</myStyle> embedded in it. </body> </html>This is a sentence with a"myStyle" element embedded in it. - In-line layouts can be specified with the css property
- Inline layouts are things like
CSS Inline vs. Block
display:block- Block layouts are things like
<p/>,<div/>and<li/>that cause the line of text to break- Block layouts can be specified with the css property
display: block
<html> <body> This is a sentence with a <myStyle style="display:block; border: thin red solid">"myStyle" element</myStyle> embedded in it. </body> </html>This is a sentence with a"myStyle" element embedded in it. - Block layouts can be specified with the css property
CSS Box Model
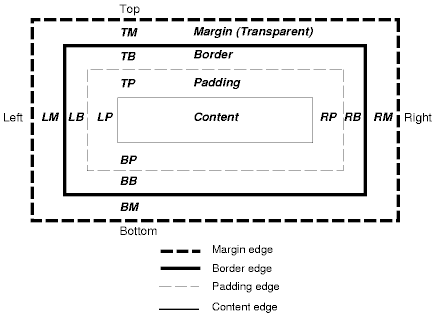
- CSS Box model: margins, borders, and padding
- CSS uses three values for each side of the box when laying out an element:
margin-top,-bottom,-left, and -right:- the transparent area around the element
border-top,-bottom,-left, and -right:- the area for the border that will be painted around the element
padding-top,-bottom,-left, and -right:- the area between the actual content and the border
- Gives you detailed control of the spacing of elements relative to each other
- Box width and height are specified by
width andheight , respectively - Units can be in % of surrounding element, ems, or px (pixels)
- CSS uses three values for each side of the box when laying out an element:
CSS Summary
- Best way to learn CSS:
- Find something you like on the web
- Figure out how they did it (use View→Page Source)
- Set up a small example and try it!
- Use Firefox, check out the many helpful extensions:
- Tools→Web Developer→Error Console in Firefox
- Tools→Web Developer→Firebug in Firefox
Questions on CSS?
The Document Object Model
- The Document Object Model (DOM)
is a cross-language standard for representing XML documents as trees
- One node for each element, attribute, or text
- Pro:
- Much easier to manipulate trees than strings
- Same basic model in many different languages (which lowers the learning cost)
- Con:
- Needs a lot of memory for large documents
- Generic standard doesn't take advantage of the more advanced features of some languages
- Python's standard library includes a simple implementation of DOM called
minidom- Fast, sturdy, and well documented…
- …if you understand all the terminology, and know more or less what you're looking for
The Basics
- Every DOM tree has a single root representing the document as a whole
- Doesn't correspond to anything that's actually in the document
- This element has a single child, which is the root node of the document
- It, and other element nodes, may have three types of children:
- Other elements
- Text nodes
- Attribute nodes
DOM Tree Example
![[A DOM Tree]](swc/lec/img/xml/dom_tree.png)
Figure 6: A DOM Tree
<root> <first>element</first> <second attr="value">element</second> <third-element/> </root>
More On Tree Structure
- Every node keeps track of what its parent is
- Allows programs to search up the tree, as well as down
- Note: it's easy to forget that text and attributes are stored in nodes of their own
- Other Python libraries like
ElementTreeuse dictionaries instead - Pro: makes simple things a little simpler
- Con: not (yet) part of the standard library
- Other Python libraries like
Creating a Tree
- Usual way to create a DOM tree is to parse a file
<?xml version="1.0" encoding="utf-8"?>
<planet name="Mercury">
<period units="days">87.97</period>
</planet>
import xml.dom.minidom
doc = xml.dom.minidom.parse('mercury.xml')
print doc.toxml('utf-8')
<?xml version="1.0" encoding="utf-8"?> <planet name="Mercury"> <period units="days">87.97</period> </planet>
Converting To Text
- The
toxmlmethod can be called on the document, or on any element node, to create text - DOM trees always store text as Unicode
, so when you're converting the tree to text, you must tell the library how to represent characters
- Example above uses UTF-8 , which is the best default choice
- See The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) for the details
- This means that strings taken from XML documents are Unicode, not ASCII
-
import xml.dom.minidom my_xml = '''<name>Donald Knuth</name>''' my_doc = xml.dom.minidom.parseString(my_xml) name = my_doc.documentElement.firstChild.data print 'name is:', name print 'but name in full is:', repr(name)name is: Donald Knuth but name in full is: u'Donald Knuth'
- Note the
uin front of the string the second time it is printed- A simple
printstatement converts the Unicode string to ASCII for display
- A simple
-
Other Ways To Create Documents
- Can also create a tree by parsing a string
import xml.dom.minidom src = '''<planet name="Venus"> <period units="days">224.7</period> </planet>''' doc = xml.dom.minidom.parseString(src) print doc.toxml('utf-8')<?xml version="1.0" encoding="utf-8"?> <planet name="Venus"> <period units="days">224.7</period> </planet>
Other Ways To Create Documents
- Or by building a tree by hand
import xml.dom.minidom impl = xml.dom.minidom.getDOMImplementation() doc = impl.createDocument(None, 'planet', None) root = doc.documentElement root.setAttribute('name', 'Mars') period = doc.createElement('period') root.appendChild(period) text = doc.createTextNode('686.98') period.appendChild(text) print doc.toxml('utf-8')<?xml version="1.0" encoding="utf-8"?> <planet name="Mars"><period>686.98</period></planet>
- Notice that the output of the preceding example wasn't nicely indented
- Because we didn't create text nodes containing carriage returns and blanks
- Most machine-generated XML doesn't
The Details
-
xml.dom.minidomis really just a wrapper around other platform-specific XML libraries- Have to reach inside it and get the underlying implementation object to create the
documentnode - That node then knows how to create other elements in the document
- Middle argument to
createDocumentspecifies the type of the document's root node - Documentation explains what the first and third arguments to
createDocumentare
- Have to reach inside it and get the underlying implementation object to create the
- Add new nodes to existing ones by:
- Asking the document to create the node
- Appending it to a node that's already part of the tree
- Set attributes of element nodes using
setAttribute(attributeName, newValue)- Remember, all attribute values are strings
- If you want to store an integer or a Boolean, you have to convert it yourself
Finding Nodes
- Often want to do things to all elements of a particular type
- E.g., find all
<experimenter/>nodes, extract names, and print a sorted list
- E.g., find all
- Use the
getElementsByTagNamemethod to do this- Returns a list of all the descendents of a node with the specified tag
import xml.dom.minidom
src = '''<heavenly_bodies>
<planet name="Mercury"/>
<planet name="Venus"/>
<planet name="Earth"/>
<moon name="Moon"/>
<planet name="Mars"/>
<moon name="Phobos"/>
<moon name="Deimos"/>
</heavenly_bodies>'''
doc = xml.dom.minidom.parseString(src)
for node in doc.getElementsByTagName('moon'):
print node.getAttribute('name')
Moon Phobos Deimos
Walking a Tree
- Often want to visit each node in the tree
- E.g., print an outline of the document showing element nesting
- Node's type is stored in a member variable called
nodeType-
ELEMENT_NODE,TEXT_NODE,ATTRIBUTE_NODE,DOCUMENT_NODE
-
- If a node is an element, its children are stored in a read-only list called
childNodes - If a node is a text node, the actual text is in the member
data
Recursive Tree Walker
import xml.dom.minidom
src = '''<solarsystem>
<planet name="Mercury"><period units="days">87.97</period></planet>
<planet name="Venus"><period units="days">224.7</period></planet>
<planet name="Earth"><period units="days">365.26</period></planet>
</solarsystem>
'''
def walkTree(currentNode, indent=0):
spaces = ' ' * indent
if currentNode.nodeType == currentNode.TEXT_NODE:
print spaces + 'TEXT' + ' (%d)' % len(currentNode.data)
else:
print spaces + currentNode.tagName
for child in currentNode.childNodes:
walkTree(child, indent+1)
doc = xml.dom.minidom.parseString(src)
walkTree(doc.documentElement)
solarsystem TEXT (1) planet period TEXT (5) TEXT (1) planet period TEXT (5) TEXT (1) planet period TEXT (6) TEXT (1)
Modifying the Tree
![[Modifying the DOM Tree]](swc/lec/img/xml/modify_tree.png)
Figure 7: Modifying the DOM Tree
- Modifying trees in place is a little bit tricky
- Helps to draw lots of pictures
- Example: want to emphasize the first word of each paragraph
- Get the text node below the paragraph
- Take off the first word
- Insert a new
<em/>element whose only child is a text node containing that word
Complications
- But what if the first child of the paragraph already has some markup around it?
- E.g., what if the paragraph starts with a link?
- Could just wrap the first child with
<em/>- But if (for example) the link contains several words, this will look wrong
- We'll ignore this problem for now
Solution
- Step 1: find all the paragraphs using
getElementsByTagName, and iterate over themdef emphasize(doc): paragraphs = doc.getElementsByTagName('p') for para in paragraphs: first = para.firstChild if first.nodeType == first.TEXT_NODE: emphasizeText(doc, para, first)
Solution
- Step 2: break the paragraph text into pieces, and handle each piece in turn
- Create a new node for each piece
- Push it onto the front of the paragraph's child list
- Once they've all been handled, get rid of the original text node
def emphasizeText(doc, para, textNode): # Look for optional spaces, a word, and the rest of the paragraph. m = re.match(r'^(\s*)(\S*)\b(.*)$', str(textNode.data)) if not m: return leadingSpace, firstWord, restOfText = m.groups() if not firstWord: return # If there's text after the first word, re-save it. if restOfText: restOfText = doc.createTextNode(restOfText) para.insertBefore(restOfText, para.firstChild) # Emphasize the first word. emph = doc.createElement('em') emph.appendChild(doc.createTextNode(firstWord)) para.insertBefore(emph, para.firstChild) # If there's leading space, re-save it. if leadingSpace: leadingSpace = doc.createTextNode(leadingSpace) para.insertBefore(leadingSpace, para.firstChild) # Get rid of the original text. para.removeChild(textNode)
Not Finished Yet
- Part 3: test it
- Yes, it really is part of programming
-
if __name__ == '__main__': src = '''<html><body> <p>First paragraph.</p> <p>Second paragraph contains <em>emphasis</em>.</p> <p>Third paragraph.</p> </body></html>''' doc = xml.dom.minidom.parseString(src) emphasize(doc) print doc.toxml('utf-8')<?xml version="1.0" encoding="utf-8"?> <html><body> <p><em>First</em> paragraph.</p> <p><em>Second</em> paragraph contains <em>emphasis</em>.</p> <p><em>Third</em> paragraph.</p> </body></html>
Summary
- There's a lot of hype in hypertext
- Haven't yet heard anyone claim that XML will cure the common cold, but I'm sure it's been said
- Pros:
- One set of rules for people to learn
- Never have to write a parser again
- At least, the low-level syntactic bits—still need to figure out what all those tags mean
- Cons:
- Raw XML is hard to read
- Particularly if it has been generated by a machine
- A lot of data isn't actually trees
- When storing a 2D matrix or a table, you have to organize data by row or by column…
- …either of which makes the other hard to access
- There are a lot of complications and subtleties
- Most applications ignore most of them
- Which means that they fail (usually badly) when confronted with something outside the subset they understand
- Raw XML is hard to read
- Like Inglish speling, it's here to stay